

近期因爲其他老師討論一些專案,因此把以前的Open CV拿出來用一下,發現真的不太順,因此查了一下近期還有哪些不錯的模型可以使用?結果真的是科技日新月異,都不一樣了,有很多新出來的模型真的頗好用的。
這邊拿了幾個搜尋起來大家比較推薦的視覺辨識模型(OpenCV, YOLOv11 Pose, YOLOv11n, RT-DETR)來測試一下,分別針對運作時的「FPS (幀率)、Inference Time (推論時間)、物件偵測數量以及系統資源使用率」進行比較。
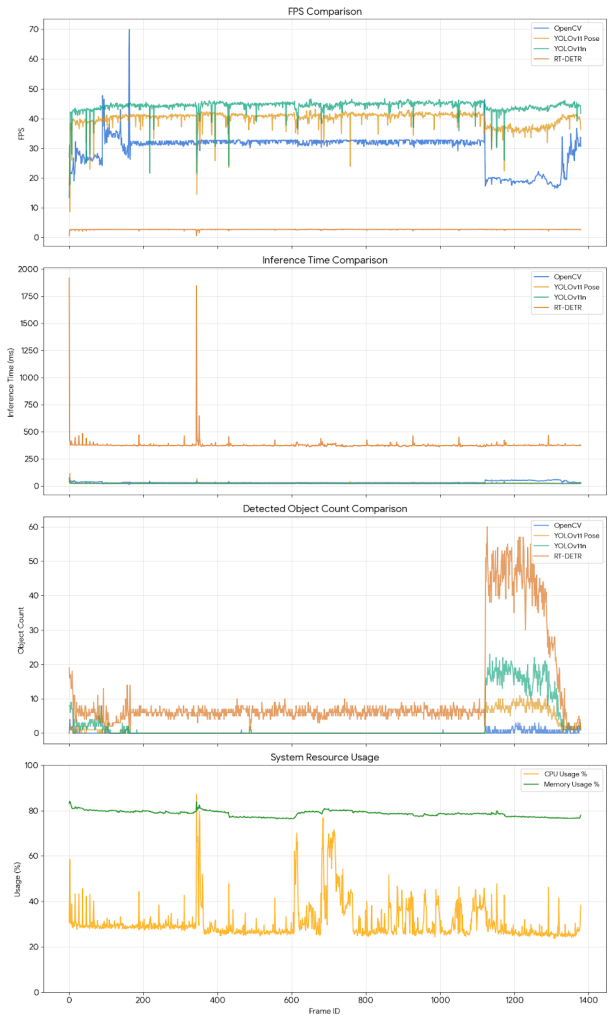
效能測試結果分析
直上結果,從折線圖與統計數據中,我們可以觀察到明顯的差異(測試環境:MacBook Pro M4 16G):
1. 速度與幀率(FPS)(說明:越快越好)
- YOLOv11n(Nano) 表現最優異,平均 FPS 達到 44.1 FPS,推論時間僅需 22.7 ms。這顯示 Nano 版本非常適合需要高即時性的應用。
- YOLOv11 Pose 緊追在後,平均 FPS 約 39.9 FPS,在進行姿態估計的同時仍保持極高的流暢度。
- OpenCV 平均約 29.7 FPS,速度中規中矩。
- RT-DETR 明顯最慢,平均僅 2.7 FPS,推論時間高達 378 ms。這顯示該模型雖然精度高(詳見下方偵測數量),但運算負擔極大,若無高階 GPU 加速,難以應用於即時場景。
2. 偵測能力(Object Count)- 敏感度差異
- RT-DETR(紅色線)偵測到的物件數量最多(平均 10-20 個),這可能意味著它的召回率(Recall) 較高,能抓到其他模型忽略的小物件或背景物體,但也需注意是否有誤判(False Positive)。
- YOLOv11n(綠色線)相當穩定,持續偵測到約 8 個物件。
- OpenCV(藍色線)偵測到的數量最少且波動大,這顯示傳統電腦視覺方法在複雜場景下的穩定性不如深度學習模型。
3. 系統資源(Resource Usage)
- 我使用MAcBook Pro M4,為了確認系統穩定,因此還是記錄一下CPU等硬體使用率。CPU 使用率穩定維持在 30%-45% 之間,記憶體使用率則維持在 83% 左右,顯示測試過程系統負載相對穩定。
測試結論
- 若追求極致速度與即時反應,YOLOv11n 是最佳選擇。
- 若需要姿態資訊,YOLOv11 Pose 的效能損失非常小,CP 值很高。
- RT-DETR 在此硬體配置下不適合即時應用,但其高敏感度適合用於後處理或靜態影像分析。
- 而過去大家熟知的OpenCV,自己覺得就是時代眼淚了,當然很多影像辨識分析的基礎我還是需要安裝一下這個模型,但就真的是老前輩了。
然後我就請AI幫我說明一下,OpenCV和這次測試其他的模型,在架構上我應該如何思考他的差異?以下是說明:
流程 A:OpenCV (傳統方法)
這是一個「逐步拼接」的過程,每一步都需要人工調整參數。
原始圖片 ➔ 前處理 (轉灰階/去噪) ➔ 特徵提取 (尋找邊緣/角點/顏色) ➔ 分類器 (SVM/決策樹) ➔ 輸出結果
- 關鍵技術: Canny 邊緣檢測、SIFT/ORB 特徵點、HOG (方向梯度直方圖)、Haar Cascades。
- 你的角色: 你像個工匠,手動調整每個步驟的過濾器。
流程 B:深度學習 (YOLO/RT-DETR)
這是一個「黑盒子」過程,輸入圖片,直接輸出結果。
原始圖片 ➔ 深度神經網路 (數百層卷積運算) ➔ 輸出結果 (類別 + 位置)
- 關鍵技術: CNN (卷積神經網路)、Transformer (注意力機制)、Backpropagation (反向傳播更新權重)。
- 你的角色: 你像個教練,準備好教材 (資料集),讓學生 (模型) 自己去學,你只負責看它考試成績 (Loss/mAP) 好不好。
